Over the past month or so, I have been dealing with a lot of questions around the troubleshooting failover scenarios for Availability Groups. So I decided that it is now time for me to pen down a post on the data to be collected and analysis options for digging into the root cause for an Availability Group. I did have time on my hands and decided to induce a Hollywood element into this post as well. The availability group name that I would be using in this post is named as Fluffy. Fluffy has two secondary Availability Replicas: one synchronous and the other one an asynchronous replica.
As you can see in the screenshot below, I had initiated a failover for my Availability Group and the AlwaysOn
Extended Events sessions shows a state change. The Extended Events session writes to a target file (.xel) which is present in the SQL Server LOG folder.
The Extended Event session runs by default when an Availability Group is configured on the SQL Server instance. The following extended events are captured by the Event Session:
- sqlserver.alwayson_ddl_executed,
- sqlserver.availability_group_lease_expired,
- sqlserver.availability_replica_automatic_failover_validation,
- sqlserver.availability_replica_manager_state_change,
- sqlserver.availability_replica_state_change,
- sqlserver.error_reported
Note that the Extended Events session will only track the state changes for the local replica. The Extended Events session is NOT a global store for all the state change events for all replicas!

The previous set of logs that you collect from the SQL Server failover cluster instances like the SQL Errorlog, Cluster log and Windows Event logs are still applicable for root cause analysis for failovers. However, now you have additional logs in the SQL Server LOG folder which can assist with a root cause analysis for failover issues. The screenshot below shows two new files that would be of interest when analyzing SQL Server failovers namely, the AlwaysOn_health_* and <server name>_<instance name>_SQLDIAG_* logs. The first set of files are the AlwaysOn Extended Events logs and the second set of logs are called the Failover Cluster Instance Diagnostics Log.
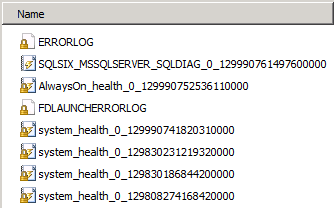
We already saw from the above screenshot what the AlwaysOn Extended Events health session can track. Now, let’s see what the Failover Cluster Instance Diagnostics Log collects. There will be multiple informational messages about the activities performed against the Availability Group. Additionally, there will be messages pertaining to the sp_server_diagnostics data (component_health_resultset) collection and the Availability Group state change (availability_group_state_change).
The T-SQL query below can help you fetch the state change information for your SQL Server instance. Again, this is specific to the instance from which you fetched the failover cluster instance diagnostics log:
select object_name,cast(event_data as xml) as xmldata
from sys.fn_xe_file_target_read_file('<file name/path>', null, null, null)
where object_name = 'availability_group_state_change'
A snippet of the XML data retrieved using the above query for the manual failover that I had done is shown below:
<data name=”target_state“>
<value>2</value>
<text>Online</text>
</data>
<data name=”failure condition level“>
<value>3</value>
<text >SYSTEM_UNHEALTHY</text>
</data>
…
…
<data name=”availability_group_name”>
<value>FLUFFY</value>
</data>
…
</event>
In summary, the following sets of logs need to be collected from all the Availability Replicas:
- SQL Server Errorlog from the time of the failure
- Windows Application and System Event logs from the time of the failure
- All the Failover Cluster Instance Diagnostics log (upto a maximum of 10 rollover .xel files by default)
- All the AlwaysOn Extended Event session log files (upto a maximum of 4 rollover .xel files by default)
- System Health Session Extended Event session files (optional as the component health state information is present in #4)
- Windows Cluster log
There are some useful queries in the Books Online topic for the failover cluster instance diagnostics log to parsing through the collected data.
Happy troubleshooting!!
P.S. The above blog post was created using a lab environment provided by SQL Server Virtual Labs. This is an online environment which allows you to create virtual machines to practice various SQL Server scenarios. The lab that I used was “SQL Server 2012: AlwaysOn Availability Groups (SQL 142)“.

